How much are your 9's worth?
Making your 9’s look great by cheating.


I realize that I am lucky.
I am lucky enough to have gotten a job at GitHub, where I am allowed to work on software that impacts a lot of developers lives every day. I’m also lucky enough to have stumbled into reliability work, which has allowed me to participate in meetings with customers, vendors and executives to talk about reliability.
Because of those meetings I tend to get pulled back into the world of nines, either because someone in one of those meetings mentioned how many nines they have or because I am looking back at history and wondering what kind of nines we are offering.
What’s in a nine?
It turns out that nines are a tricky thing. A single number can have a lot of flaws (you can read your nines are not my nines to understand the amount of pain those flaws can cause).
All nines are not created equal. Most of the time I hear an extraordinarily high availability claim (anything above 99.9%) I immediately start thinking about how that number is calculated and wondering how realistic it is.
Stripe says they have 99.9999% availability and Twilio says they have 99.999% availability. Do they really? I guess it depends on what they are measuring and how rigorously they are measuring it.
Depending on how you measure your availability you can probably make all sorts of 9’s claims. But are they worth anything? Is it possible to abstract your availability into a single set of 9’s?
Why have a single number at all?
Certainly, when someone is talking about “how many nines” they have, they are indirectly implying they have a single number that measures their availability and it meets or exceeds some number of 9’s.
The engineer in you may now be asking why we want to have a single number representing such a complex system. Surely it is a leaky abstraction that can’t get close enough to be useful.
Human beings are funny, though. It turns out we respond pretty well to simplicity and order. For example, take a look at this chart:
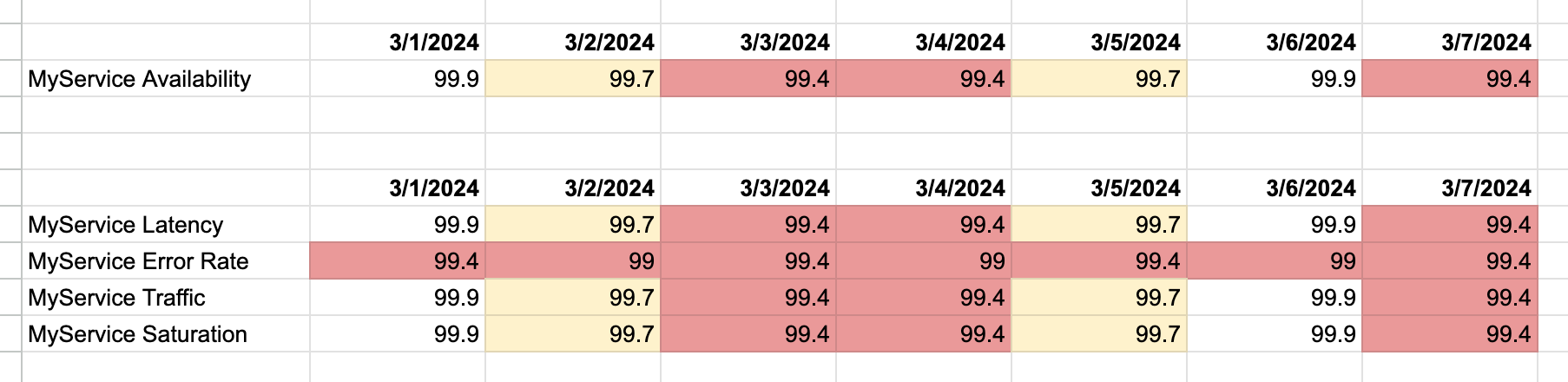
Which section is easiest to reason about? The section with 4 numbers or the section with one?
Having a single number to measure service health is a great way for humans to look at a table of historical availability and understand if service availability is getting better or worse. It’s also the best way to create accountability and measure behavior over time…
… as long as your measurement is reasonably accurate and not a vanity metric.
How to cheat your 9’s
Rather than write about how to create a number that holds you rigorously accountable for the blood, sweat and tears you’re shedding in the availability realm it is a lot more fun to examine all of the ways we can cheat to make the number look better.
Last time I covered a variety of different mechanisms for aggregating your nines and I may reference some of those calculations below.
Cheat #1 - Measure the narrowest path possible.
This is the easiest way to cheat a 9’s metric. Many nines numbers I have seen are various version of this cheat code. How can we create a narrow measurement path?
Only measure “uptime” as when we ping the website or an HTTP request succeeds on the home page. The actual page could be totally broken, or every other page could be broken, but we can count success as “the request went through”.
Only measure the “golden path”. We can pick a single customer journey (for example, a customer can log in and check their home page). We then only measure that path but ignore all of the other customer interactions.
Cheat #2 - Lump everything into a single bucket.
Not all requests are created equal.
Think about how many times the stylesheet is loaded for this blog. It’s probably a pretty small and static asset. It’s probably loaded by a deluge of scrapers and bot traffic we don’t care about. I bet it has a very successful request rate.
Now think about how many times I press the “Post” button when I write a blog post. Clicking “Post” is very important to me but the number of posts I have written so far is probably less than 20. And I bet the “post” mechanism is a lot more prone to failure.
In order to make our metrics look good we need to make sure to bucket the post requests in with the stylesheet requests when we measure error rate. This way those failures will get masked by the deluge of bot stylesheet requests.
We will have great nines with extraordinarily unhappy customers.
Cheat #3 - Don’t measure latency.
This is an availability metric we’re talking about here, why would we care about how long things take, as long as they are successful?!
How long did it take this post to load? If it took 30 seconds, would you have closed your browser already? What about 10 seconds? What about 2? At some point latency crosses into availability and if we want to make our metrics look as good as possible we should absolutely not consider this.
Cheat #4 - Measure total volume, not minutes.
Let’s get a little controversial.
Here is a contrived incident example so we can think about availability in more concrete terms.
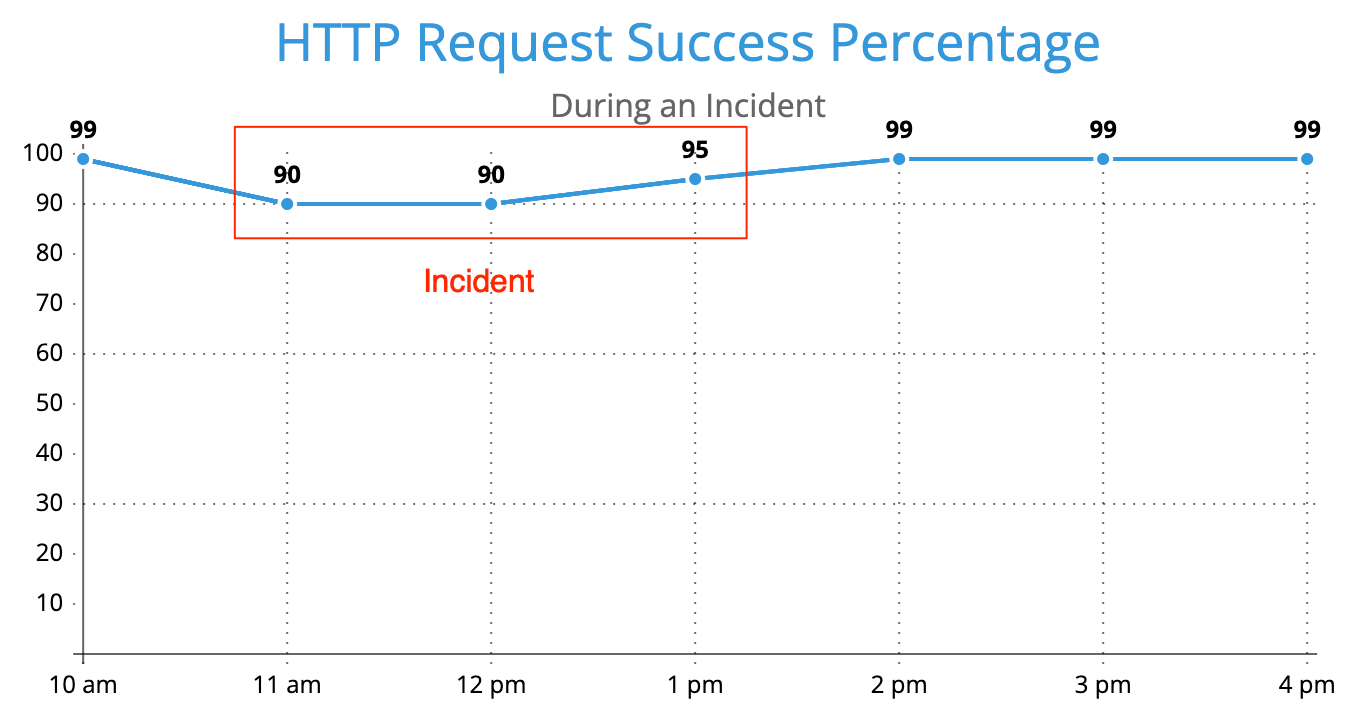
Now let’s calculate the availabiilty over this time frame using two different approaches…
Daily Availability (overall success rate) = (99+90+90+95+99+99+99) / 7 = 95.8%
Daily Availability (hours above 99%) = 4 hours / 7 hours = 57.1%
As you can see above, the “minutes down” approach is pessimistic. Even though not every request was failing for this time frame, we still count the minutes as “down”.
In order to cheat the metric we want to choose the calculation that looks the best, since even though we might have been having a bad time for 3 hours (1 out of every 10 requests was failing), not every customer was impacted so it wouldn’t be “fair” to count that time against us.
The example above assumes a constant request rate for every hour. If we assume that during the incident people stopped hitting the website because they realized it was broken, then the total number of failures would be even less, making the total volume approach even more optimistic.
Are we really trying to cheat?
Of course, this post is a bit tounge in cheek and it’s not fair to think of all of the mechanisms described above as “cheating”.
In reality there are a lot of very practical reasons for taking some of these shortcuts. For example:
We don’t have data on all of the customer scenarios. In this case we just can’t measure enough to be sure what our availability is.
Building more specific models of customer paths is manual. It requires more manual effort and customization to build a model of customer behavior (read: engineering time). Sometimes we just don’t have people with the time or specialization to do this, or it will cost to much to maintain it in the future.
Sometimes we really don’t care (and neither do our customers). Some of the pages we build for our websites are… not very useful. Sometimes spending the time to measure (or fix) these scenarios just isn’t worth the effort. It’s important to focus on important scenarios for your customers and not waste engineering effort on things that aren’t very important (this is a very good way to create an ineffective availability effort at a company).
Mental shortcuts matter. No matter how much education we try, it’s hard to change perceptions of executives, engineers, etc. Sometimes it is better to pick the abstraction that helps people understand than pick the most accurate one.
Data volume and data quality are important to measurement. If we don’t have a good idea of which errors are “okay” and which are not, or we just don’t have that much traffic, some of these measurements become almost useless (what is the SLO of a website with 3 requests? does it matter?).
This is all very dry and abstract, so in my next post I’ll spice it up by taking a look at some public SLAs and see how people are putting these different techniques to use.